LiLAS @ CLEF2021
The Living Labs for Academic Search (LiLAS) lab aims to strengthen the concept of user-centric living labs for the domain of academic search by allowing participants to evaluate their retrieval approaches in two real-world academic search systems from the life sciences and the social sciences. To this end, we provide participants with metadata on the systems’ content as well as candidate lists with the task to rank the most relevant candidate to the top. Using the STELLA-infrastructure, we allow participants to easily integrate their approaches into the real-world systems and provide the possibility to compare different approaches at the same time.
Schedule for 21 September 2021
All times are for the main conference location Bucharest (GMT+3). For more detailed information regarding registration and the official programme of CLEF 2021 check the official CLEF 2021 website. Don’t forget to register for CLEF 2021!
| Time | Topic |
|---|---|
| 15:30 | Introduction and Welcome, Overview and Tasks (Philipp Schaer) |
| 15:45 | STELLA Infrastructure and Tech Details of LiLAS (Timo Breuer) |
| 16:00 | Presentations of Participating Teams |
| 16:30 | Results (Timo Breuer) |
| 16:45 | Discussion and Outlook (Leyla Jael Garcia) |
| 17:00 | End of Session |
Updates
- 16 September: Please register for CLEF 2021!
- 17 May: Round 2 ended and results were sent to the praticipating groups! Please remember to submit your workshop notes until 28 May.
- 30 March 2021: Round 1 ended yesterday and click feedback data is available at https://th-koeln.sciebo.de/s/OBm0NLEwz1RYl9N
- 21 March 2021: Schedule and information on click feedback updated.
- 1 March 2021: Round 1 started for task 2! New LIVIVO data for tasks 1 released. Please download the data sets again to have the latest fixes for your systems available. We will adapt the LIVIO time schedule to allow to include these fixes.
- 28 January 2021: Extended task descriptions is available.
- 14 January 2021: Information on the STELLA evaluation framework we use in LiLAS is available.
- 14 December 2020: Datasets are available at https://th-koeln.sciebo.de/s/OBm0NLEwz1RYl9N
Tasks for CLEF 2021
LiLAS offers two different evaluation tasks:
- Ad-hoc retrieval of scientific documents for the multi-lingual and multi-source Life Science search portal LIVIVO.
- Research dataset recommendation within the Social Science portal GESIS Search: Given a scientific publication find relevant research data sets (out of a list of candidates).
For both tasks, participants are invited to submit
- Type A : pre-computed runs based on previously compiled queries (ad-hoc search) or documents (research data recommendations) from server logs or
- Type B : Docker containers of full running retrieval/recommendation systems that run within our evaluation framework called STELLA.
For type A, participants pre-compute result files following TREC run file syntax and submit them for integration into the live systems. For type B, participants encapsulate their retrieval system into a Docker container following some simple implementation rules inspired by the OSIRRC workshop at SIGIR 2019.
The details of the two tasks are described seperately.
Data Sets
We publish two datasets to allow participants to train and compile their systems for the two platforms LIVIVO and GESIS Search. We offer a list of candidate documents and candidate research data for each query and seed document, respectively, so participants focus on the actual ranking approaches behind the ad-hoc search and recommendation task: https://th-koeln.sciebo.de/s/OBm0NLEwz1RYl9N
The data sets share a common struture:
├── gesis-search
│ ├── candidates
│ ├── datasets
│ ├── documents
├── livivo
│ ├── candidates
│ ├── documents
For both platforms we release the documents/research data sets and a precompiled set of candidate documents. For further data set documentation, please refer to the documentation included in the repository.
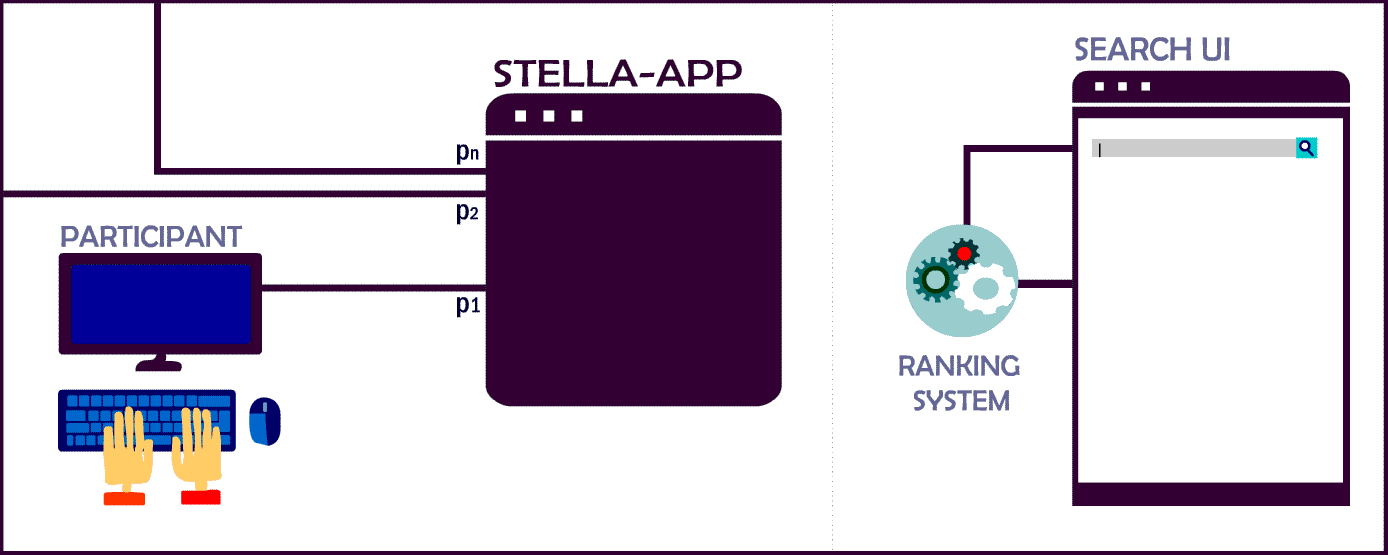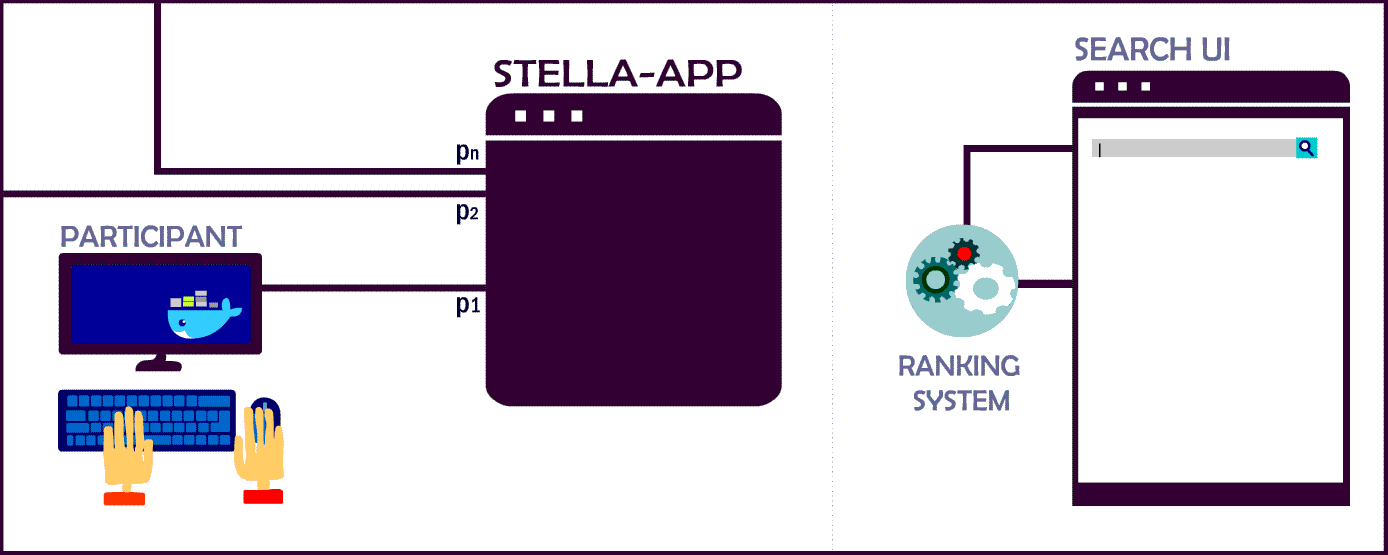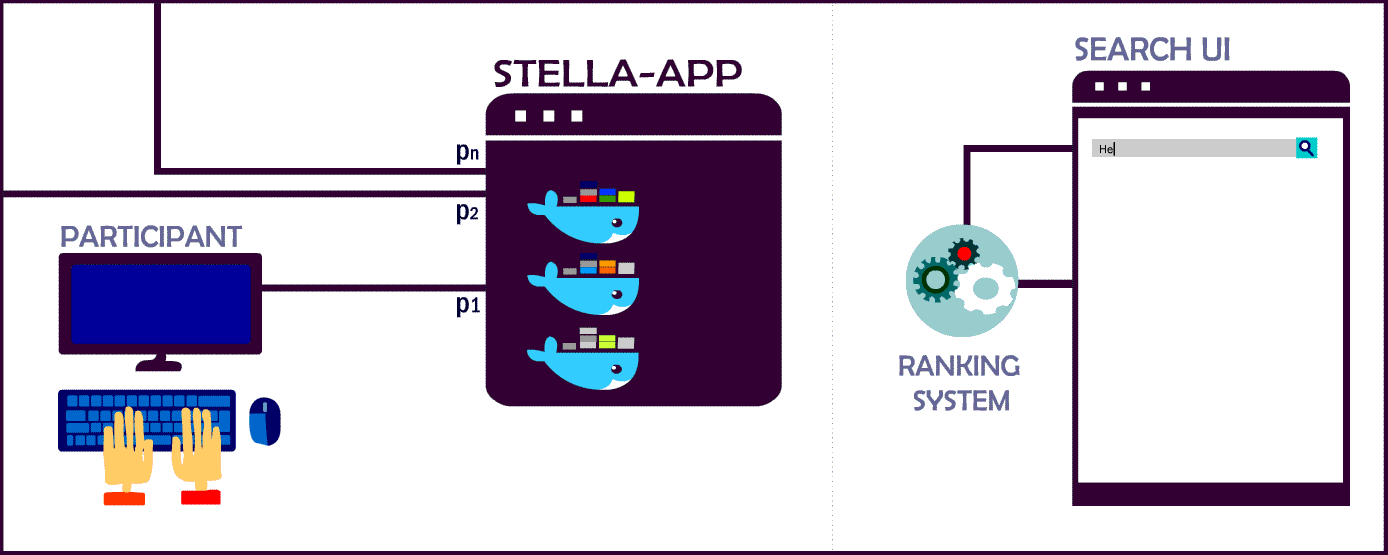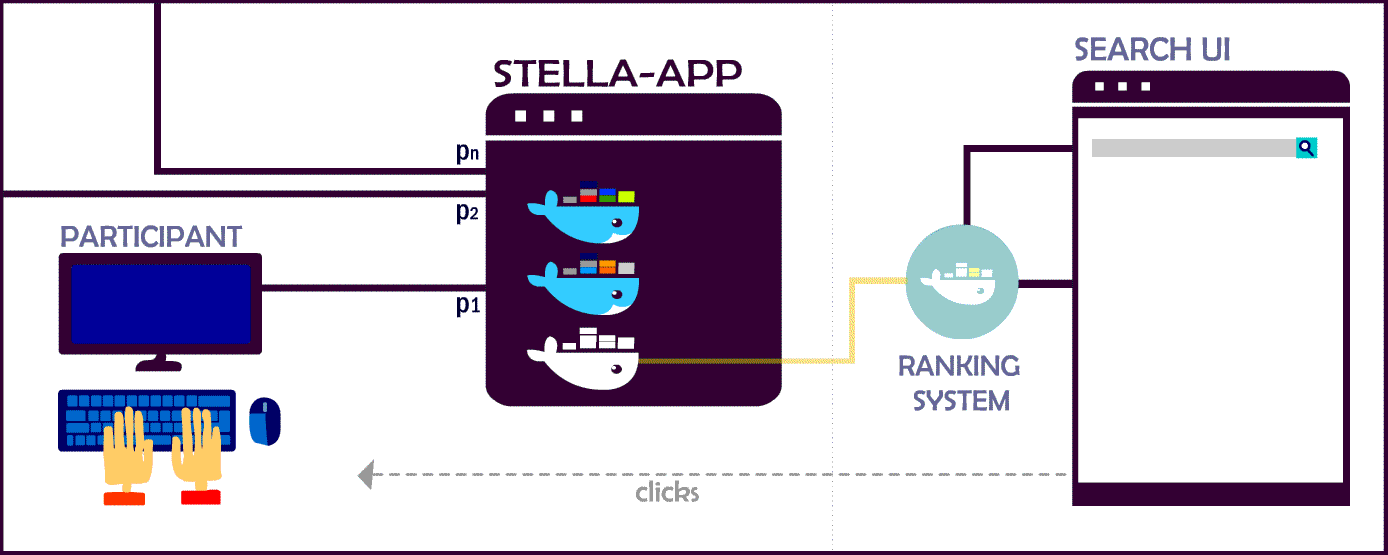
Feedback and Evaluation Metrics
For both we use an interleaving between the experimental systems and the baseline productive system. Within GESIS Search we track clicks on the dataset records. Within LIVIVO we track the following click events:
- set bookmark
- show details
- show fulltext
- instock (shows Information about location etc. if document is in ZB MED holdings)
- more_links (one of the links, listed under “more links” clicked)
- order (order document from ZB MED)
- title (title/headline clicked)
Using these events we compute wins, ties and losses against the production baseline system.
STELLA Evaluation Framework
We use the STELLA framework to include your rankings and recommendations!
Currently, the infrastructure supports two different types of submission. Experimenters can choose to submit pre-computed runs with TREC run file syntax OR use this repository in order to integrate their system as a micro-service into the STELLA App. In contrast to pre-computed results, these dockerized systems can deliver more comprehensive search result since they are not limited to pre-selected queries or items.
Ressources
- Template for Type A (precomputed) submissions
- Template for Type B (Docker-based) submissions
- Tutorial on how to implement your own STELLA-based ranker
- Tutorial on how to implement your own STELLA-based dataset recommender
Dates
14 December 2020, Data releaseJanuary + February 2021, Training phase 1 - code tutorial for the living lab component will be released1 March - 28 March 2021, Round 1 for GESIS5 March - 28 March 2021, Round 1 for LIVIVO (due to technical hiccups)29 March 2021, Feedback 130 March - 11 April 2021, Training phase 212 April - 17 May 2021, Round 210 May 2021, Feedback 2- 28 May 2021, Paper Submission
For further details, please refer to the CLEF 2021 schedule
Organization
We will have a half-day workshop that is split up in two parts.
LiLAS 2020 Chairs
- Philipp Schaer, TH Köln, Germany
- Johann Schaible, GESIS, Germany
- Leyla Jael Garcia-Castro, ZB MED, Germany
Follow us
Google Groups | GitHub | lilas@stella-project.org
LiLAS is part of CLEF 2021.
![]()
![]()